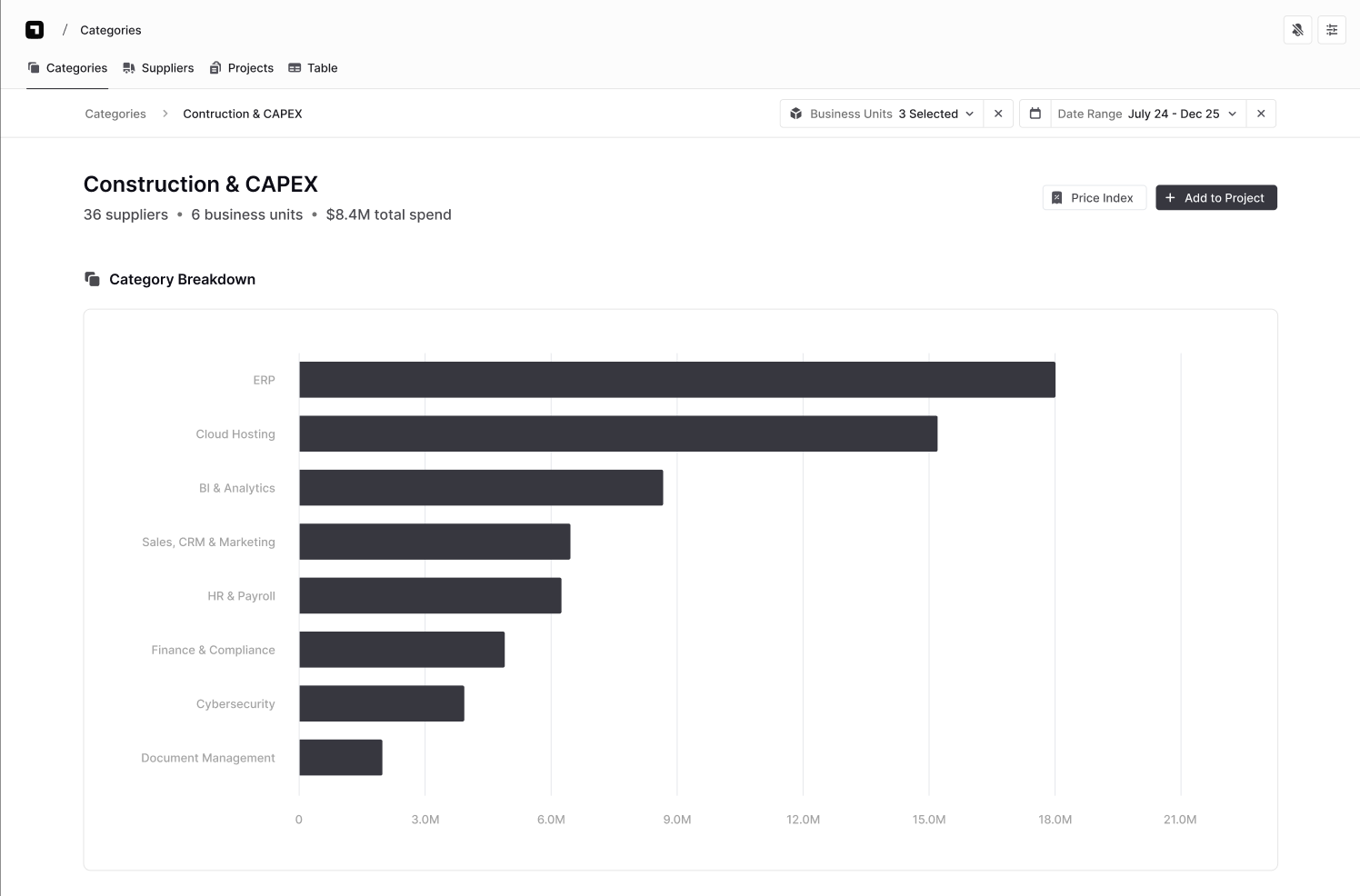
Finance teams don't reject AI spend analytics because it doesn't work—they reject it because they can't verify how it works. When a Chief Procurement Officer can't explain to their CFO why a €2M savings recommendation is credible, the tool becomes a liability rather than an asset.
The "black box" problem is about defensibility. What follows explains the actual mechanisms behind five core AI capabilities in spend analysis—not just what they do, but how they do it and what that means when you need to justify decisions to your finance team.
Automated classification: How machines learn your taxonomy
Supervised learning models are trained on your historical classification decisions. Natural language processing breaks down invoice line items into analysable features: vendor names, description patterns, amounts, department codes. The model then identifies category signals across millions of transactions and outputs a confidence score for each classification.
For example, an invoice line reads "Office supplies, printer paper, A4, 80gsm." The model parses this for category indicators:
- "Office supplies" (explicit category mention)
- "Printer" + "paper" (product type signals)
- Technical specifications (confirms low-value indirect spend category)
The output isn't binary. It's probabilistic:
- 95%+ confidence = auto-classify
- 60–95% confidence = flag for human review
- Below 60% = route to manual classification queue
Why the mechanism matters
You can audit why the model made specific decisions. That transparency matters when finance teams question your data. Confidence thresholds let you balance speed against accuracy based on spend materiality—you might auto-classify €50 office supply purchases but manually review €50K IT infrastructure decisions.
There's also a regulatory angle. The EU AI Act and GDPR require explainable AI for certain applications.
A limitation vendors often overlook: model accuracy degrades when you reorganise your taxonomy. If you consolidate or split categories, you're essentially retraining the system. Budget for ongoing validation, especially for edge cases in indirect spend where patterns are less consistent.
Data cleansing: Pattern recognition beyond simple rules
Traditional cleansing uses rules: "if field contains X, do Y." Machine learning identifies probabilistic patterns across multiple fields simultaneously—vendor name variations, duplicate invoices, currency mismatches.
Fuzzy matching algorithms go beyond exact string matches. For instance, "Siemens AG," "Siemens Germany," and "Siemens GmbH" get consolidated through similarity scoring. The model learns that these variations refer to the same economic entity even though the strings don't match exactly.
Why this matters
This solves a few specific problems:
- VAT number variations across EU member states create artificial vendor fragmentation
- Cross-border supplier data requires currency and legal entity normalisation
- Different naming conventions across languages (GmbH vs. Ltd vs. SpA)
The European Commission's cross-border procurement guidance emphasises standardised supplier data—AI cleansing makes compliance possible at scale.
Anomaly detection: Finding outliers finance teams actually care about
Here's where AI moves from efficiency to insight. Unsupervised learning establishes "normal" patterns for each spend category, supplier, and department. Statistical models identify transactions that deviate from expected patterns across multiple dimensions simultaneously.
It's not just "this price is high." It's "this price is high for this supplier, for this quantity, at this time of year, compared to this peer group."
For instance, say historical data shows your marketing team spends €8K–€12K monthly on agency services. In November, a €47K transaction appears for the same agency.
The model flags this based on:
- Amount deviation (4x typical monthly spend)
- No seasonal pattern justifying the spike
- Unusual velocity compared to historical trend
But it's not flagged as fraud because the supplier relationship is established and the transaction went through normal approval channels. That distinction matters—it reduces alert fatigue by learning what's actually abnormal versus what's just unusual.
Why this matters for defensibility
You can explain why something was flagged, not just report that "the AI said so." Models prioritise anomalies based on financial impact and risk score, so your team can focus on material issues rather than being overwhelmed by false positives.
Anomaly detection also helps identify non-compliant suppliers—missing certifications, entities on EU sanctions lists, or patterns that could indicate fraud under stricter EU financial controls.
Predictive modelling: From historical patterns to demand forecasting
Time-series analysis examines historical spend data to identify cyclical patterns, trends, and seasonality. Regression models correlate spend with external variables: production volume, headcount growth, and market indices. Ensemble methods combine multiple models to improve forecast accuracy.
For instance, the model analyses three years of raw material purchases and identifies:
- Quarterly seasonality (Q1 and Q3 typically 15% higher than Q2 and Q4)
- Correlation with production schedules
- Supplier lead time patterns
It generates: Q1 2025 expected spend = €2.3M ± €180K (confidence interval).
If actual Q1 spend hits €2.8M by February, the system triggers an early warning. That's actionable intelligence about category inflation before it compounds—or potential supplier capacity constraints.
Why this matters beyond demand planning
Finance teams need budget variance explanations that are quantified and historically grounded. "Spend is up because the AI forecasted it" doesn't work. "Spend is tracking 12% above forecast due to raw material price increases, which correlates with the Eurostat Producer Price Index trend for this category" is defensible.
European procurement teams should integrate regional economic indicators—such as energy costs, regulatory changes, and currency fluctuations—that affect spend patterns differently than those in global markets.
Natural language querying: Making data accessible without compromising accuracy
Natural language processing translates questions into structured database queries. Intent recognition identifies what you're actually asking, entity extraction pulls out key parameters (time periods, categories, suppliers), and query validation prevents impossible requests.
When a user asks, "What did we spend on IT services with German suppliers last quarter?", the model processes and translates to structured query language behind the scenes:
- Intent: aggregate spend query
- Entities: category = IT services, supplier location = Germany, time = last quarter
This democratises data access without training procurement teams on SQL or BI tools. It reduces dependency on IT for basic queries. And importantly, query logs become training data—the system learns your team's common questions and gets better at interpreting them.
The critical limitation: this is only as good as your underlying data taxonomy. Garbage in, garbage out still applies. Complex multi-step analysis still requires traditional analytics skills.
Verification is the real value proposition
The shift in AI spend analysis is from "trust the AI" to "verify the AI." Transparency is what makes these tools defensible in finance reviews.
These five mechanisms work together: automated and cleansed data improves classification accuracy, better classification improves anomaly detection, and cleaner insights enable more reliable forecasting.
When evaluating AI spend analysis tools, ask vendors:
- How is confidence scored for classifications?
- What happens to low-confidence decisions?
- Can I audit why specific classifications or anomalies were flagged?
- How does the model handle taxonomy changes?
Prioritise vendors who build explainability into the product—not just for GDPR compliance, but for CFO conversations. The EU's guidelines on trustworthy AI emphasise transparency and accountability. Your spend analysis tools should meet that standard.

